
Prophet문서를 하나하나 살펴보다 보니, Prophet에도 cross validation을 적용할 수 있다는 것을 알게 되었다. 그리고 원하는 지표를 기준으로 CV하면서 그리드서치로 하이퍼파라미터를 정할 수 있다. 그것도 병렬로해서 조금 더 빠르게도 가능! 해당 부분을 정리해봤다.
Cross Validation
Prophet에서의 교차검증은 과거 데이터에서 컷오프(절단) 지점을 선택하고, 그 전까지만 사용해서 모델을 피팅하고 그 이후의 값으로 모델을 평가하면서 진행된다.

위 사진을 기준으로 보면, cutoff지점인 2013년도를 기준으로 이전은 initial이라는 학습 기간으로, 이 기간을 대상으로 모델이 학습되고 이후 horizon으로 된 기간을 예측해서 모델을 평가하게 된다. 지금 horizon 기간은 365로 설정되어 있기 때문에 1년이 표시되어 있는데, 즉 1년간의 데이터를 가지고 학습한 모델을 평가한다고 이해하면 된다.
from prophet.diagnostics import cross_validation
m = Prophet()
m.fit(df)
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days',parallel="processes")cross validation을 사용하기 위해서는 먼저 Prophet모델을 만들고, 트레인 데이터셋을 가지고 fit을 먼저 시켜야 한다. 이후 해당 모델을 가지고 cross_validation에 넣고 나머지 요소들을 설정해주면 되는데 기본적으로 설정해야하는 파라미터는 다음 3개다.
- initial : 학습기간
- period : 학습-평가를 옮길 기간
- horizon : 평가 기간
조금 더 상세히 설명하자면,
위의 모델은 initial이 730 days로 되어 있으니 730일의 데이터를 학습하는 모델이 만들어지고 horizon이 365 days이므로 최초 730일 이후 365일을 예측하고 해당 일들에 대해서 평가를 하게 된다. 첫 날부터 730일 되는 날이 위의 그래프에 있는 cutoff지점이 된다. 이런 학습 - 평가 루틴은 period설정 기간마다 반복되는데, 현재는 180 days로 되어 있으니 약 6개월씩 옮겨가면서 실행된다.
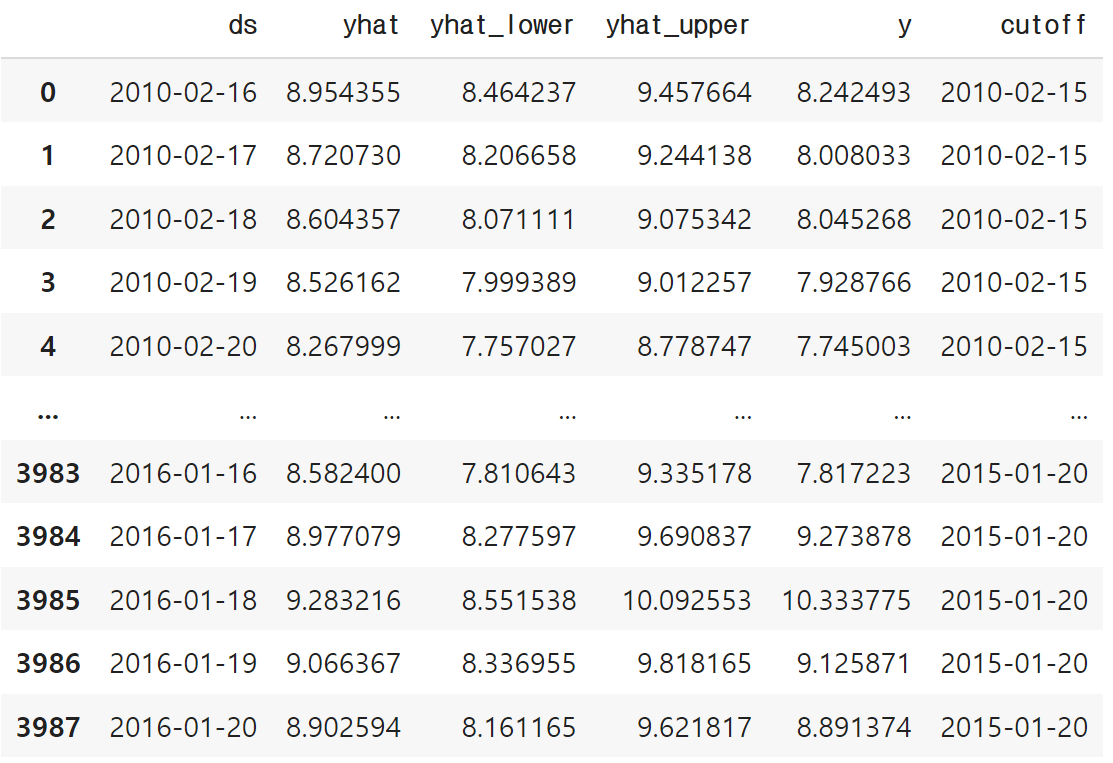
cv 결과를 보면 각 cutoff날짜와 그에 따라 예측한 날짜와 예측값, 예측 상/하한값, 실제값을 볼 수 있는데

period = 180 days로 설정이 되어 있으므로 약 6개월마다 cutoff지점이 설정되어 있는 걸 볼 수 있다.
그리고 개인적으로 가장 좋았던 점은 병렬처리가 가능하다는 점이다. 위에서 맨 뒤에 있는 parallel을 이용하면 되는데,
None, processes, threads, dask 이렇게 네 가지 옵션이 있다.
- None : 기본값, 아무 것도 설정하지 않음
- processes : 아마 멀티프로세스
- threads : 아마 멀티쓰레드
- dask : dask를 이용한 처리
너무 크지않은 문제인 경우 기본적으로 parallel = "processes"를 추천하고 있다. 너무 크다면 dask를 이용하면 되는데 이 때 dask는 자동으로 설치되지 않으니 따로 설치해서 사용하면 된다.
이렇게 parallel을 설정해서 하니까 자꾸 warning관련한 로그가 찍혀 나와서 굉장히 거슬리는데, 실행하기 전에 logging을 이용해서 setLevel을 설정해주면 나름 깔끔해진다. (그래도 기본적인 로그는 나온다)
import logging
logging.getLogger('prophet').setLevel(logging.WARNING)
CV 정리
헷갈릴 것 같아서 다시 정리하자면,
initial='730 days', period='180 days', horizon = '365 days' 로 설정한 경우
- 2010년 2월 15일(첫번째 cutoff지점) 이전 730일을 학습하고 이후 365일을 예측해서 평가
- 180일을 옆으로 이동해서
2010년 8월 14일(두번째 cutoff지점) 이전 730일을 학습하고 이후 365일을 예측해서 평가 - 또 다시 180일을 옆으로 이동해서
2011년 2월 10일(세번째 cutoff지점) 이전 730일을 학습하고 이후 365일을 예측해서 평가
이런 식으로 180일씩 옆으로 이동해가면서 학습 - 예측 - 평가를 반복해서 진행하게 된다.
병렬 처리를 원한다면 parallel 파라미터를 이용하면 된다.
Custom cutoff
당연히 학습이 수행되는 cutoff지점을 직접 설정이 가능하다.
cutoffs = pd.to_datetime(['2013-02-15', '2013-08-15', '2014-02-15'])
df_cv2 = cross_validation(m, cutoffs=cutoffs, horizon='365 days')데이터프레임 형식으로 cutoff_df를 만들고, cutoffs에 전달해주면 되는데 이 때 cutoff 지점 이전이 학습 기간이 자동으로 설정되는 것 같다. 이후 어느정도의 기간을 예측하고 평가할지 알려줘야 하기 때문에 horizon은 꼭 설정해줘야 한다.
CV 평가
cv진행한 결과를 이용해서 많이 쓰는 다양한 평가 지표들을 바로 볼 수 있는 performance_metrics가 있다.
from prophet.diagnostics import performance_metrics
-- rolling_window = 0.1이 기본값
df_p = performance_metrics(df_cv, rolling_window=0.01)위의 df_p결과로는 horizon, mse, rmse, mae, mape, mdape, sampe, coverage를 볼 수 있다.


여기서 horizon은 cutoff로부터 해당 days까지의 지점이다. horizon을 설정할 지점은 rolling_window를 조절해서 설정할 수 있는데, 이 숫자는 %라고 생각하면된다. 1로 설정하면 365days만 나오고, 위의 결과는 0.01로 설정했기 때문에 365 * 0.01 = 3.65로 4 days가 처음으로 나왔다. 즉, 4일까지의 예측치의 각 통계값들을 보여준다. 너무 긴 기간을 한번에 예측하게 되면 당연히 결과 정확성이 떨어지니 horizon을 보고 최적 예측 기간을 설정하도록 만들어 둔 것 같다.
Hyperparameter tuning
위에서 알아봤던 Cross validation을 이용해서 prophet에 들어가는 다양한 하이퍼파라미터들을 조절할 수 있는데, 문서에서는 이전 포스팅에서 썼던 방법 말고 다른 방법을 이용해서 설명하고 있다.
import itertools
import numpy as np
import pandas as pd
param_grid = {
'changepoint_prior_scale': [0.001, 0.01, 0.1, 0.5],
'seasonality_prior_scale': [0.01, 0.1, 1.0, 10.0],
}
cutoffs = pd.to_datetime(['2013-02-15', '2013-08-15', '2014-02-15'])
# 파라미터 조합 생성
all_params = [dict(zip(param_grid.keys(), v)) for v in itertools.product(*param_grid.values())]
rmses = []
# 파리미터 평가를 위해 cv진행
for params in all_params:
m = Prophet(**params).fit(df)
df_cv = cross_validation(m, cutoffs=cutoffs, horizon='30 days', parallel="processes")
df_p = performance_metrics(df_cv, rolling_window=1)
rmses.append(df_p['rmse'].values[0])changepoint_prior_scale과 seasonality_prior_scale 두가지를 조절했고, RMSE를 기준으로 평가를 진행한다. rolling_window가 1이니까 가져올 RMSE는 horizon의 가장 최대기간인 30일의 값이다.
tuning_results = pd.DataFrame(all_params)
tuning_results['rmse'] = rmses
print(tuning_results)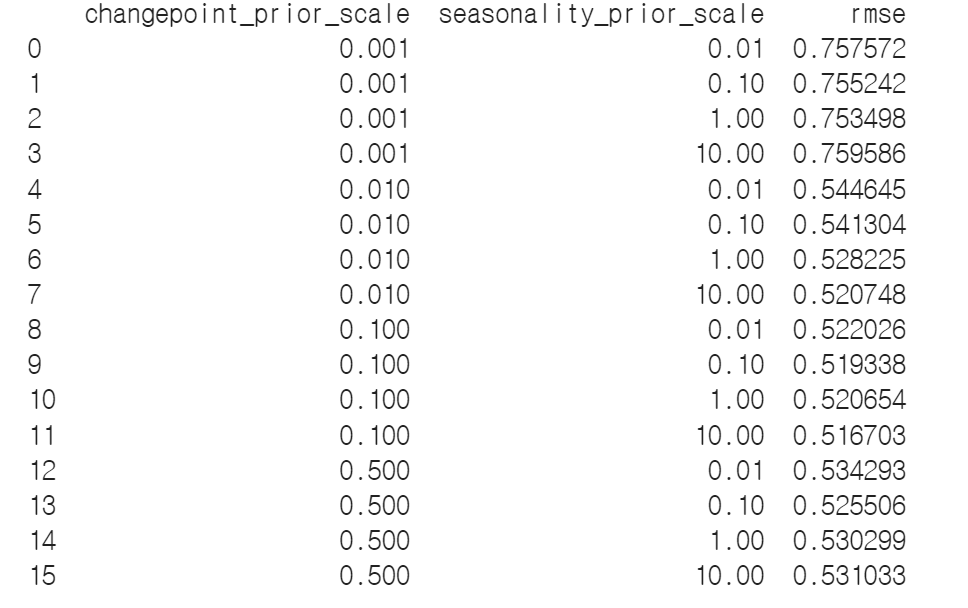
각 파라미터와 그에 따른 결과는 위와 같이 확인이 가능하고
best_params = all_params[np.argmin(rmses)]np.argmin을 이용해서 rmse기준 가장 좋은 파라미터 조합을 선택할 수 있다.
조절할 수 있는 파라미터들 / 아마 조절 가능할 것들 / 못하는 것들을 나누어서 설명해주고 있는데
- 조절 가능한 것들
changepoint_prior_scale, seasonality_prior_scale, holidays_prior_scale, seasonality_mode - 아마도 조절 가능할 것
changepoint_range - 조절 안되는 것들
growth, changepoints, n_changepoints, yearly/weekly/daily_seasonality, holidays 등등
참고해서 활용하면 좋을 것 같다.
parallel을 설정해서 그런건지 아니면 문서에서 나온 hyperparameter tuning방법이 더 효과적이라서 그런건지는 모르겠는데 동일한 파라미터들을 설정해서 실행했을 때, 위에 소개한 방법대로 하면 CV까지 했음에도 불구하고 훨씬 더 빨리 결과를 볼 수 있었다. 아주 좋다.
'AI > 시계열' 카테고리의 다른 글
| Deep Learning for Anomaly Detection in Time-Series Data: Review, Analysis, and Guidelines (5) | 2024.10.27 |
|---|---|
| [시계열] 시계열 데이터의 패턴과 성능 평가, 이동 평균으로 간단 예측하기 (2) | 2024.01.07 |
| [Python] prophet 사용하기 3 - changepoint 조절하기, Gridsearch로 최적 파라미터 찾기 (0) | 2022.07.24 |
| [python] prophet 사용하기 2 - Seasonality 조절하기 (0) | 2022.07.19 |
| [python] prophet 사용하기1 - holiday 옵션 조절하기 (0) | 2022.07.13 |