728x90
Abstract
- Long sequence time-series(LSTF)에서는 입-출력 사이의 장거리 의존성 커플링을 진단할 수 있는 모델이 필요함
- 최근의 연구에서 트랜스포머가 이 잠재력을 보여주었으나, 3가지 문제점이 있음
- 2차 시간 복잡도(quadratic time complexity)
- 높은 메모리 사용량
- 인코더-디코더 아키텍처의 고유한 제한 등
- 이러한 문제를 해결하기위해 Informer를 제안
- Informer의 특징
- O(L logL)의 시간복잡도, 메모리 사용량을 가지는 Probsparse self-attention 매커니즘
- 계단식으로 인풋을 절반으로 줄여 효과적으로 긴 인풋 시퀀스를 다룸
- 개념적으로 단순한 generative style decoder를 이용해 긴 시퀀스 예측의 속도를 크게 향상시킴
INTRODUCTION

- 기존의 방법들은 대부분 짧은 기간의 시계열 예측에 적합하게 설계되어 있음
- 그림 a는 짧은 기간 예측과 긴 기간 예측을 표현한 것
- 그림 b에서 볼 수 있듯이 추론 예측 길이가 길어질수록 오류는 증가, 추론 속도는 감소함 기준 : 48
- LSTF의 주된 목표는 long sequence에 대한 prediction capacity를 향상시키는 것 이를 위해 다음 두 가지가 필요함
- 긴 범위에 대한 정렬 능력 long-range alignment ability
- 긴 시퀀스의 입출력에 대한 효율적인 연산능력 efficient operations on long sequence input/output
- 트랜스포머는 self-attention 매커니즘을 사용하여 긴 범위의 의존성을 포착하는 데에는 성공했지만, L길이의 인풋-아웃풋에 대해서 L차 계산과 메모리 사용으로 인해 2번을 위반하게 됨.
- 긴 길이로 갈수록 크리티컬한 문제이기 때문에 다음의 질문에 대한 답을 찾고자 함
- 트랜스포머 모델을 더 높은 예측 능력을 가지면서도 연산, 메모리, 구조를 효율적으로 개선할 수 있을까?
-
- The quadratic computation of self-attention
Self-attention에서는 각 레이어별 연산이 O(L^2)의 시간복잡도 및 메모리 사용량을 가짐 - The memory of bottleneck in stacking layers for long inputs
J개의 쌓여진 인코더,디코더 레이어가 있을 때, 총 메모리 사용량은 O(J*L^2) 가 되고, 이는 모델의 확장성을 제한하는 요소가 됨 - The speed plunge in predicting long outputs
한 단계 씩 추론하기 때문에 긴 시점을 예측하면 할수록 속도가 느려짐바닐라 트랜스포머의 한계점 3가지
- The quadratic computation of self-attention
- 선행 연구들의 경우 주로 self-attention의 효율성 문제만을 해결하고자 함 (1번)
- 그렇기에 1~3번 모두를 만족하는 모델 제안
- 논문의 기여점
- 긴 시계열의 아웃풋-인풋 의존성을 포착 할 때 transformer-like모델의 잠재력 입증
- ProbSparse self-attention 매커니즘 제안.
→ O(L log L) 시간복잡도와 메모리 사용량을 달성 - self-attention distilling operation을 제안.
→ 총 공간 복잡도를 O((2-e)LlogL) 까지 줄이고, J stacking 레이어들에서 attention score를 지배할 수 있음 - generative style decoder 제안.
→ 긴 길이의 아웃풋을 한 번의 forward step만으로 얻어낼 수 있음
MAIN IDEA
Preliminary
- 시계열 예측 방법론은 두가지로 나눠볼 수 있음
- Classical time-series models
- 확률 통계적 방법론, 고전 머신러닝 방법론
- Deep Learning techniques
- RNN등을 이용한 encoder-decoder 기반의 모형
Input Representation

- Scalar : d_model의 차원으로 projection 시킨 값
- Local Time Stamp : 일반적 transformer의 positional embedding 방식으로 고정 위치 값 사용
- Global Time Stamp : 사용자에 따라서 주, 월, 공휴일 등의 정보를 사용자 스스로 구축해서 사용
Encoder & Decoder 구성

- 왼쪽
- 인코더는 녹색의 긴 시퀀스를 인풋으로 받고, ProbSparse self-attention을 사용함
- 파란색 사다리꼴 부분은 지배적인 attention을 추출하고 network size를 줄이기 위한 self-attention distilling operation을 의미
- 복제된 옆의 작은 사이즈 인코더는 모델의 robustness를 증가시키는 역할
- 오른쪽
- 디코더가 긴 시퀀스를 인풋으로 받고 있음
- 예측해야 하는 부분은 0으로 패딩 된 상태
- 해당 인풋을 받아서 인코더에서 생성된 concatenated feature map과 encoder-decoder attention을 수행하여 한 번에 주황색 부분을 예측
Methodology
Efficient Self-attention Mechanism

- 기존의 self-attention(canonical self-attention)은 Q,K,V(Query, Key, Value)를 기반으로 정의되어 Quadratic한 횟수의 dot product 연산과 O(L_Q* L_K)만큼의 메모리 사용량을 필요로 함
- → prediction capacity 향상에 제약사항이 됨
- 이를 극복하기 위한 다양한 Sparse Attention등은 휴리스틱한 방법론을 따르고 있음을 지적
- sparsity 한 self-attention은 꼬리가 긴 분포를 가지며, 소수의 dot-product pairs만이 주요 어텐션에 기여한다는 것을 파악함.
- 영향이 없을수록 유니폼한 분포를 가지고 있음
- 분포의 유사도를 비교하여 관측된 attention 분포가 유니폼 분포(기준값)보다 큰 값을 가지고 있다면 유의미한 페어라고 판단 할 수 있음
→ 이를 바탕으로 유의미한 쿼리 몇 개만 가지고 어텐션을 계산 - 계산량과 메모리 사용량 모두 감소(O(LlogL))하며, multi-head인 경우 각 헤드별로 다른 query-key쌍을 생성하기 때문에 심각한 정보 손실도 방지
Encoder
: Allowing for Processing Longer Sequential Inputs under the Memory Usage Limitation
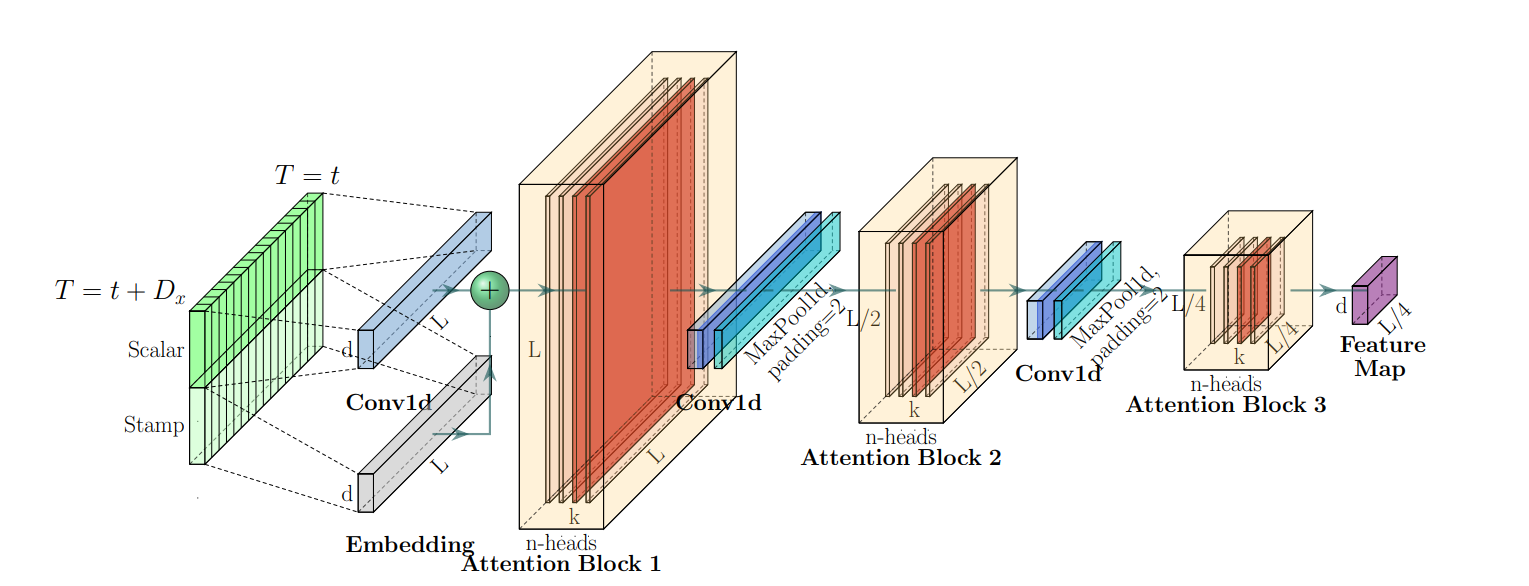
- Encoder embedding
- Scalar와 Stamp embedding을 합쳐 최종 embedding 구성
- self-attention distilling
- ProbSparse self-attention 후 convolution& max pooling을 통해 distilling 수행
- attention output 으로부터 주요한 정보만을 추출, 다음 레이어에 전달할 정보 구성을 위함
- 다음 레이어는 이전 레이어의 절반의 크기로 구성(96→48→24)하면서 메모리 사용량을 줄여 메모리 병목현상을 해결하고자 함
- Stacking layer replicas
- Robustness의 향상을 위해서 원래 인풋의 절반 길이만 인풋으로 받는 복제된 인코더를 추가로 구성
Decoder
: Generating Long Sequential Outputs Through One Forward Procedure

- One forward procedure로 Generative inference를 수행할 수 있는 디코더 구성
- Masked self-attention은 인코더와 동일하게 ProbSparse self-attention사용
- FC layer을 통해 최종 아웃풋 예측
- Loss는 MSE사용
CONCLUSION
- 긴 시계열 예측에 있어 트랜스포머의 한계를 보완하기 위해 Informer 제안
- 트랜스포머가 가지는 Quadratic한 연산 복잡도, 높은 메모리 사용량, 속도 문제를 개선할 수 있는 방법론 제시
논문 링크 : https://arxiv.org/pdf/2012.07436
728x90
'AI' 카테고리의 다른 글
| SimTS: Rethinking Contrastive Representation Learning for Time Series Forecasting (0) | 2025.02.14 |
|---|---|
| Attention is all you need (2/2) - Multi-head attention (0) | 2024.11.24 |
| Attention is all you need (1/2) - Scaled Dot Product Attention (0) | 2024.11.10 |
| [Anomaly detection] Isolation Forest (0) | 2024.03.14 |