728x90
Abstract
- 최근의 연구에서는 고정 길이 임베딩 유도를 위해 랜덤 triplet 샘플링을 기반으로 하는 triplet loss formulation을 제안함
- triplet loss
- 비교 기준인 anchor를 두고, positive / negative sample과 비교하는 손실함수
- positive와의 거리는 가깝게, negative와의 거리는 멀게 되어야 함
- 참고링크 : https://soobarkbar.tistory.com/43
- 논문에서 anchor, positive / negative sample의 선택 방법을 제시
JUSTIFICATION
- 논문에서 다룰 것
- anchor의 선택
- positive / negative sampling
- raw signal space, embedding space상에서의 탐색
- 기여점
- time series representation learning에서 contrastive triplet selection에 대해 연구함
- anchor selection with similarity based triplet mining이 random triplet selection보다 우수하다는 것을 입증함
- 즉, anchor와 가장 유사한 positive샘플, 가장 덜 유사한 negative 샘플을 선택해서 학습하는 것이 랜덤으로 선택하는것보다 더 효과적으로유사한 패턴의 학습이 가능하다는 것
MAIN IDEA
Triplet loss를 사용하려면 anchor, positive sample, negative sample이 필요함
CONTRASTIVE LEARNING WITH TRIPLETS FOR TIME SERIES

- D : 트레이닝 데이터 셋yi중의 일부를 xref로 선택, 그리고 그 중 일부를 xpos로 선택
- xneg는 다른 time series인 yj중 일부에서 선택
- yi∈Rm×Si : m은 feature, Si: 타임스탬프
- 이렇게 얻은 xref,xpos,xneg를 가지고 다음과 같은 obj function을 설정
- x^{ref},x^{pos}는 가깝게, xref,xneg는 멀게 하는 embedding space를 찾는 것
- 일반적인 t-loss는 positive sample을 하나만 쓰는데 여기는 K개를 쓰는 것이 다름
- Timeseries y를 d-dim으로 매핑하는 인코더를 학습함
- 결국 각 샘플들을 어떻게 뽑을 것 인지에 대한 문제
- 논문에서 제시한 부분
- Anchor : variation이 가장 큰 subserires를 선택함
- Positive/negative : Anchor와 유클리디안 거리가 가장 가깝/먼 subseries를 선택
ANCHOR SELECTION
- 각 timestamp별로 variation을 구해서, variation이 큰 부분부터 anchor의 범위를 늘려가는 방식
- 미리 윈도우사이즈 w와, threshold θ를 정해 놓음
- MA로 각 timestep별 variation 계산
- Variation이 가장 큰 timestep을 중심으로 지정하고( ˜p(0)) 그걸 기준으로 start는 앞쪽(xrefstart=˜p(0)−w), end는 뒷쪽(xrefend=˜p(0)+w)으로 확장해나감
- 선택 조건은 앞쪽 또는 뒷쪽의 variation이 사전에 설정한 threshold를 넘는 경우임.
- 선택되지 않은 timestep에 대해서 확인-추가를 반복하여 모든 timestep이 한 번 씩 anchor에 포함될 때 까지 반복
예시를 보면
- 가장 variation이 크게 나타나는 경우가 1번,
- 여기서 옆으로 확장해나감.
- 그리고 그 다음 1에 포함되지 않은 곳들 중variation이 큰 게 2번
- 이런 식으로 확장
SAMPLING OF POSITIVES & NEGATIVES

- 복원추출을 통해 anchor의 길이 이상인 subseries를 K개 선택.→ supervised는 positive는 같은 label / negative는 다른 label
- → unsupervised는 랜덤
- 각 subseries를 1 timestep씩 밀어가면서 anchor와의 유클리디안 거리를 계산
- positive는 최소, negative는 최대인 샘플을 선택
- 그 중에서 pos,neg의 길이가 anchor미만인 subseries를 랜덤하게 선택
- 총 K개의 pair탄생
- 유클리디안 거리로, positive는 가까운, negative는 먼 샘플을 뽑는게 목적
EXPERIMENT
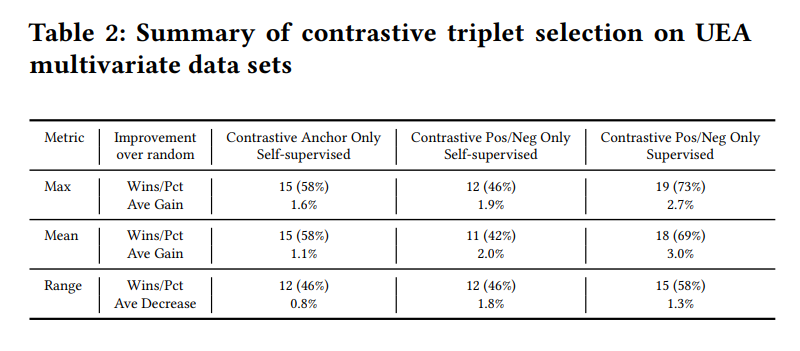
- Anchor only, pos/neg only, Both Anchor, pos/neg와 [T-Loss]의 성능을 비교
- 각 model별로 seed를 바꿔가며 5번의 실험을 진행하여 max, mean, range를 기록
- 랜덤 triplet대비 얼마나 증가했는지를 표시
Univariate의 경우

Multivariate의 경우
CONCLUSION
- Time Series representation에서 contrastive learning을 위한 anchor, positive, negative sampling에 대한 방법론
- Variation을 기준으로 anchor선택
- anchor와의 거리를 기준으로 pos, neg sample선택해서 활용
시계열 데이터에서 representation을 학습하는 경우에 랜덤샘플링이 많이 사용됨. 그러나 보다 효과적인 학습을 위한 샘플 추출을 위해서 positive / negative pairs를 어떻게 선정할지에 대한 논문.
https://dl.acm.org/doi/10.1145/3493700.3493711
728x90
'AI' 카테고리의 다른 글
| SimTS: Rethinking Contrastive Representation Learning for Time Series Forecasting (0) | 2025.02.14 |
|---|---|
| Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (0) | 2025.02.02 |
| Attention is all you need (2/2) - Multi-head attention (0) | 2024.11.24 |
| Attention is all you need (1/2) - Scaled Dot Product Attention (0) | 2024.11.10 |
| [Anomaly detection] Isolation Forest (0) | 2024.03.14 |